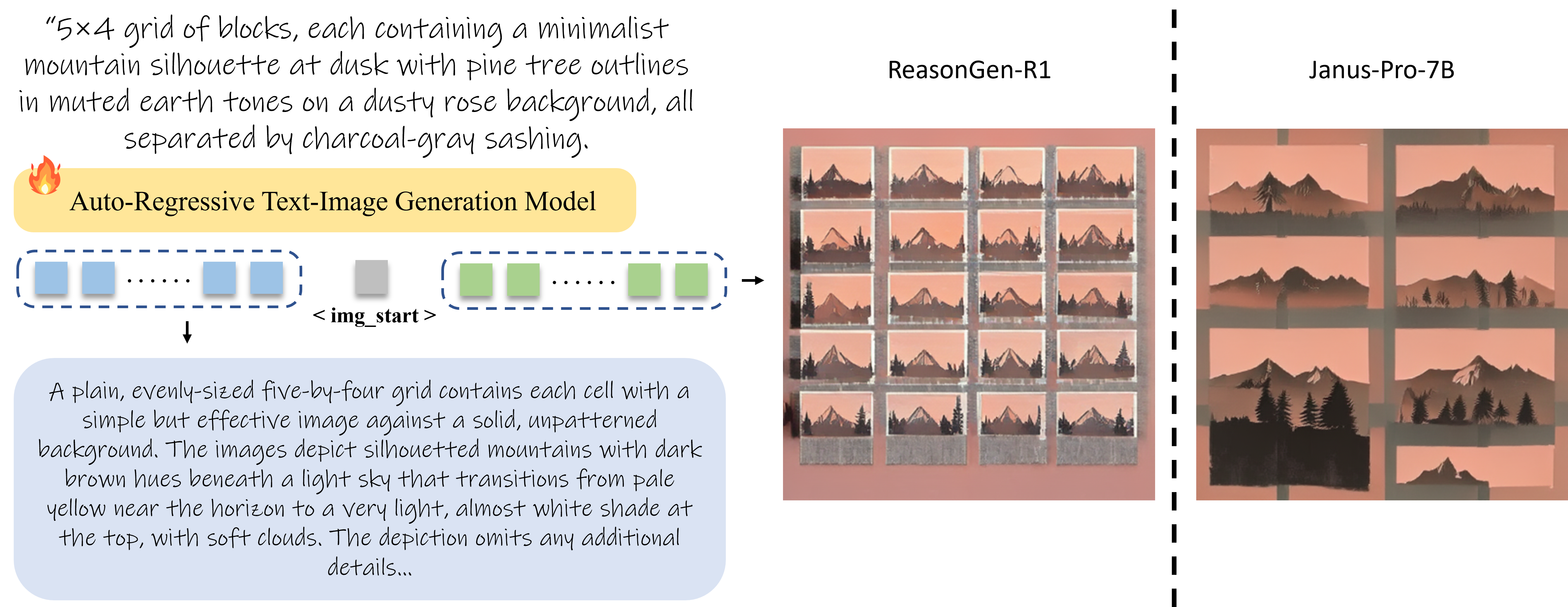
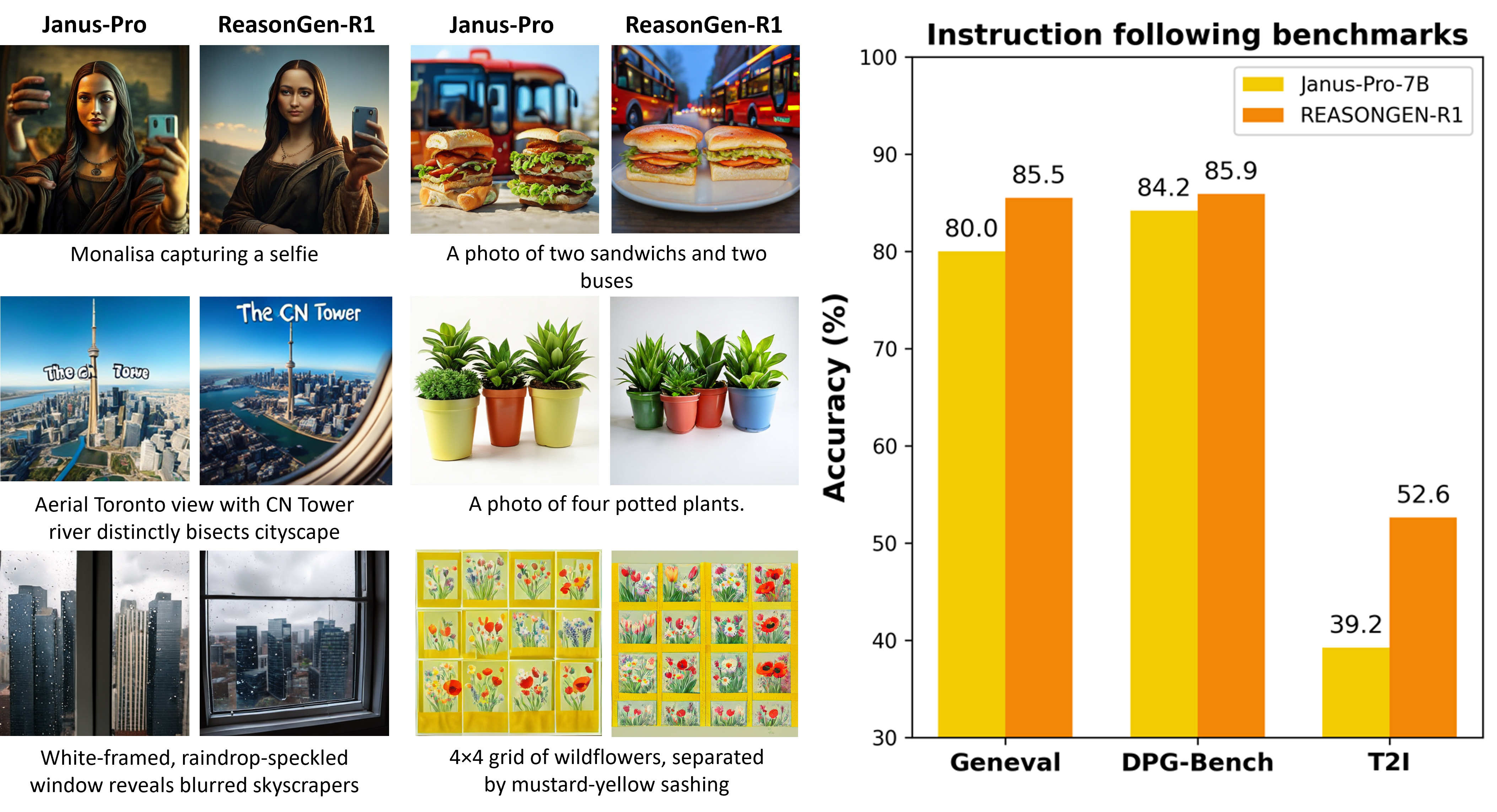
Although chain-of-thought (CoT) reasoning and reinforcement learning (RL) have driven breakthroughs in NLP, their integration into generative vision models remains underexplored. We introduce ReasonGen-R1, a two-stage framework that first imbues an autoregressive image generator with explicit text-based "thinking" skills via supervised fine-tuning (SFT) on a newly generated reasoning dataset of written rationales, and then refines its outputs using Group Relative Policy Optimization (GRPO). To enable the model to reason through text before generating images, We automatically generate and release a corpus of model-crafted rationales paired with visual prompts, enabling controlled planning of object layouts, styles, and scene compositions. Our GRPO algorithm uses reward signals from a pretrained vision–language model to assess overall visual quality, optimizing the policy in each update. Evaluations on Geneval, DPG, and the T2I benchmark demonstrate that ReasonGen-R1 consistently outperforms strong baselines and prior state-of-the-art models. We will open-source our generated reasoning dataset and training code to accelerate further advances in text-based reasoning–driven image generation.










@misc{zhang2025reasongenr1cotautoregressiveimage,
title={ReasonGen-R1: CoT for Autoregressive Image generation models through SFT and RL},
author={Yu Zhang and Yunqi Li and Yifan Yang and Rui Wang and Yuqing Yang and Dai Qi and Jianmin Bao and Dongdong Chen and Chong Luo and Lili Qiu},
year={2025},
eprint={2505.24875},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2505.24875},
}
}